PaperGuru 博客
所有文章 →Inside PaperGuru-Benchmark: Open-Sourcing Lifecycle-Aware Memory for AI Science
PaperGuru open-sources its benchmark framework and shows how Lifecycle-Aware Memory delivers state-of-the-art gains on PaperBench, SurveyBench, and real-world scientific publishing.
作者 PaperGuru Team · 2026年5月14日

The biggest bottleneck for long-horizon LLM agents in scientific research is no longer reasoning. It is memory.
When an AI agent is tasked with synthesizing 200,000 tokens of literature, tracking a methodology across multiple paper revisions, or connecting a retracted claim to downstream work, traditional memory systems break down. Flat retrieval (like standard vector databases) loses structural context. Untyped graphs lose provenance.
To solve this, we built Capital Chunk Memory (CCM), a Lifecycle-Aware Memory primitive designed specifically for the AGI era of science. Today, we are open-sourcing the evaluation framework that proves its efficacy: the PaperGuru-Benchmark repository.
The Architecture: Lifecycle-Aware Memory in Action
CCM is not a flat vector store. It is a typed, provenance-aware graph that tracks the full lifecycle of every claim, citation, and experimental artifact across long-horizon agent runs. The architecture is what allows PaperGuru to maintain coherence over 200K-token literature syntheses while still hitting >99% citation verification across OpenAlex, Semantic Scholar, arXiv, DBLP, and PubMed.
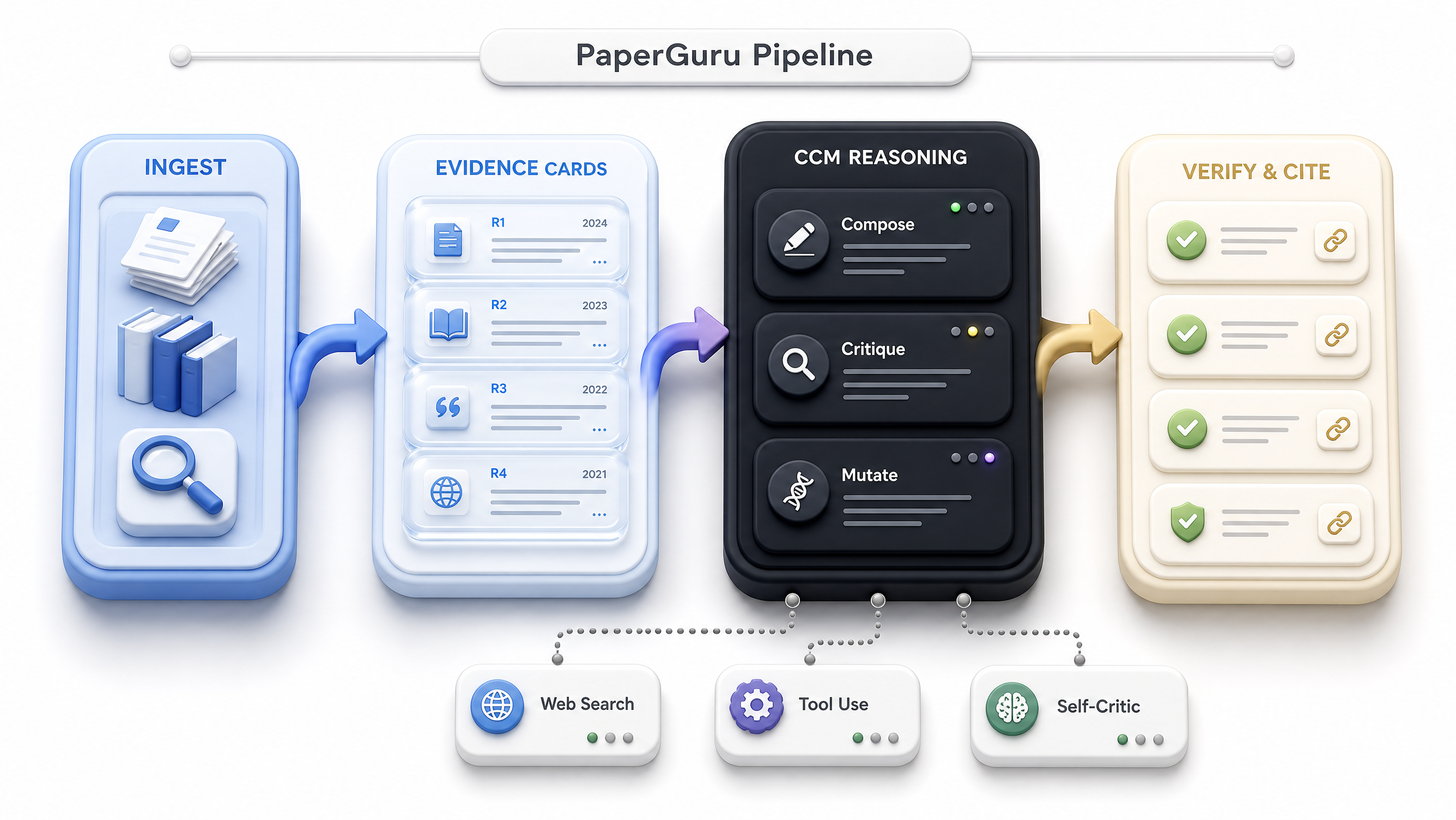
Figure 1. Capital Chunk Memory (CCM) system architecture diagram.
The Benchmark Results: PaperBench and SurveyBench
We stress-tested the CCM architecture against the two most rigorous, peer-reviewed evaluation frameworks available for AI research agents. The results demonstrate a step-function improvement over existing baselines.

Figure 2. Before vs. After: PaperGuru with Capital Chunk Memory vs. flat-retrieval baselines.
TL;DR: Headline Numbers Across Every Benchmark
Before drilling into individual benchmarks, here is the one-screen summary of how PaperGuru compares against the strongest published baselines on each dimension, plus the real-world acceptance count to date.
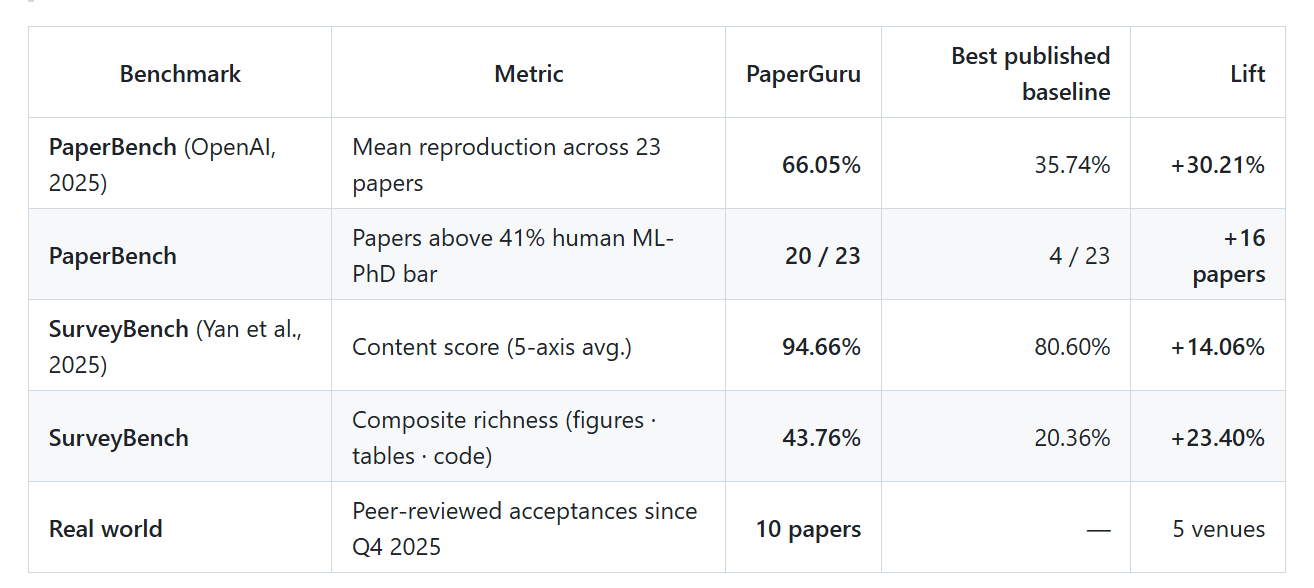
Table 1. PaperGuru vs. best published baselines on PaperBench, SurveyBench, and real-world acceptances.
PaperBench: Reproducing ML Research
PaperBench evaluates an agent's ability to reproduce the rubrics of 23 complex machine learning papers.
Performance: PaperGuru achieved a 66.05% mean reproduction score, representing a +30.21% absolute lift over the strongest baseline.
Human Expert Baseline: 20 out of the 23 papers evaluated beat the human ML-PhD expert baseline. Seven papers scored >=80%, placing them in the highest "green" tier of accuracy.
SurveyBench: Synthesizing Academic Literature
SurveyBench tests the ability to generate comprehensive, accurate academic surveys across 20 topics and 11,343 source papers.
Content Quality: PaperGuru achieved a 94.66% content score, a +14.06% lift over the next best system.
Richness: In the critical "Richness" metric, PaperGuru scored 10.94, more than double the closest competitor (5.09).
Overall: PaperGuru ranked #1 across 9 of the 11 evaluated dimensions.
The per-dimension breakdown against the four strongest open systems (AutoSurvey, LLMxMR-v2, SurveyForge, ASur) makes the gap concrete: PaperGuru leads on every single axis, with the largest absolute lifts on Coverage (+24.00%) and Depth (+17.00%).
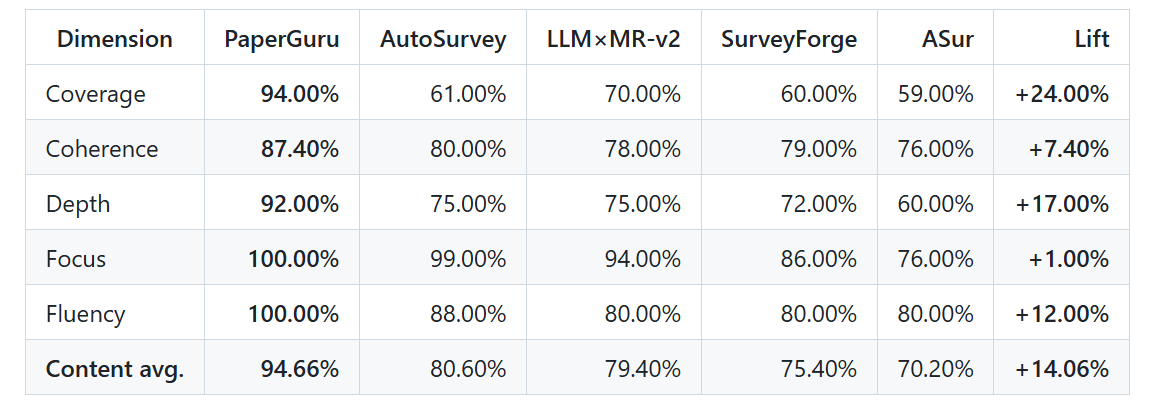
Table 2. SurveyBench per-dimension scores: PaperGuru vs. AutoSurvey, LLMxMR-v2, SurveyForge, and ASur.
From Benchmark to Production: 10 Peer-Reviewed Acceptances
Benchmarks matter, but production matters more. Within one quarter of going live, PaperGuru-assisted manuscripts have already cleared peer review at five distinct top-tier venues, concrete evidence that the CCM architecture delivers in front of real reviewers, not just rubrics.
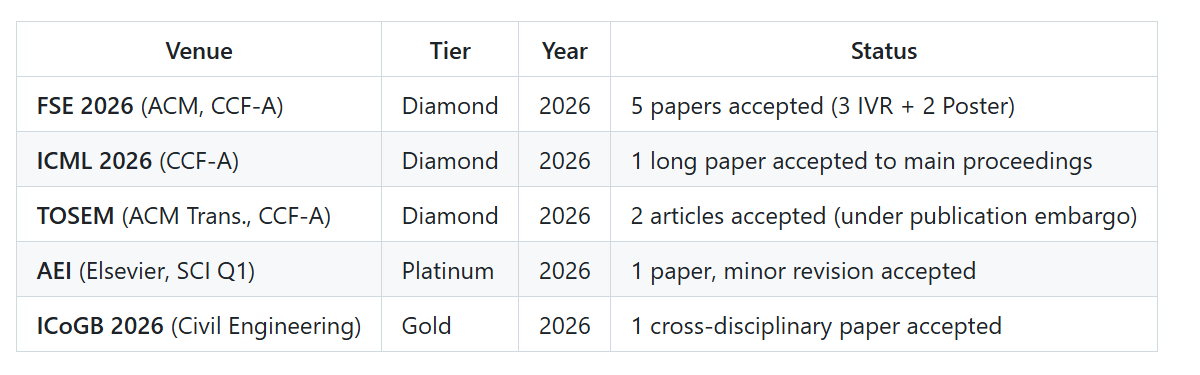
Figure 3. Real-world acceptances since Q4 2025: FSE, ICML, TOSEM, AEI, and ICoGB.
What's in the Open-Source Repository?
We believe that claims of "superhuman AI scientists" must be backed by reproducible data. The PaperGuru-Benchmark GitHub repository includes:
- The full paper: our complete NeurIPS 2026 submission detailing the Capital Chunk Memory architecture.
- Runnable code trees: 23 complete, runnable code trees from the PaperBench evaluation.
- Generated artifacts: 20 complete academic surveys generated for SurveyBench, available in PDF, Markdown, and LaTeX formats.
The Future of Agentic Memory
Lifecycle-Aware Memory is the fourth primitive of the AI infrastructure stack, sitting alongside compute, model weights, and flat retrieval. By open-sourcing our benchmarks, we invite the community to build upon, critique, and extend this architecture.
Explore the repository, read the paper, and join the discussion on our Discord:
Ready to explore?
View PaperGuru-Benchmark on GitHub and try the platform behind these benchmarks. Sign up for PaperGuru at https://paperguru.ai and get 500 free credits. Students and researchers signing up with a .edu email get an additional 500 credits (1,000 total) instantly.