PaperGuru Blog
All blog posts →PaperGuru: The Missing Memory Primitive for the AGI Era of Science
PaperGuru launches Lifecycle-Aware Memory for long-horizon scientific agents, with state-of-the-art benchmark results and early real-world paper acceptances.
By PaperGuru Team · May 9, 2026

The economics of frontier LLMs is changing faster than the systems that host them. Context windows have moved from 4K tokens to 1M tokens, and the next milestone—persistent memory across sessions—is already on every foundation lab's public roadmap. The practical consequence is that the dominant unit of LLM deployment has shifted from the single-prompt completion to the long-horizon agentic system.
We are entering the AGI era of "AI for Science." The bottleneck is no longer generation quality or reasoning ability. The bottleneck is memory.
Today, we are thrilled to announce the launch of PaperGuru, a general-purpose agentic research harness powered by a new infrastructure primitive: Lifecycle-Aware Memory (LAM). PaperGuru compresses the full academic workflow—from literature discovery and hypothesis framing to LaTeX drafting and venue submission—while maintaining strict, version-consistent provenance over unbounded archives.
The Missing Primitive in Long-Horizon Agents
Modern AI infrastructure has converged on three primitives: compute (NVIDIA), models (frontier LLM weights), and retrieval (vector databases). But a fourth—long-term memory with lifecycle semantics—has been conspicuously absent.
Production deployments today either rely on flat retrieval (which is version-blind and fails the moment the archive evolves) or on agent-specific memory hacks. None of these treat memory as a first-class system component with the properties that long-horizon agents actually need: versioned content, structural multi-hop relevance, and bounded query cost under unbounded archive growth.
Without this primitive, every long-horizon LLM system reinvents memory poorly. They hallucinate citations, lose track of canonical conventions, and fail to connect ideas across papers.
PaperGuru solves this by introducing Capital-Chunk Memory (CCM). It separates memory into compact chunk heads (a bounded routing surface) and unbounded chunk contents accessed lazily. This allows PaperGuru to route over a temporal artifact graph, unifying structural edges (cites, implements) with historical-causality edges (deprecated-by). The result: precise historical context and bounded query cost, ensuring every injected statement is traceable to a specific paper, paragraph, and version.
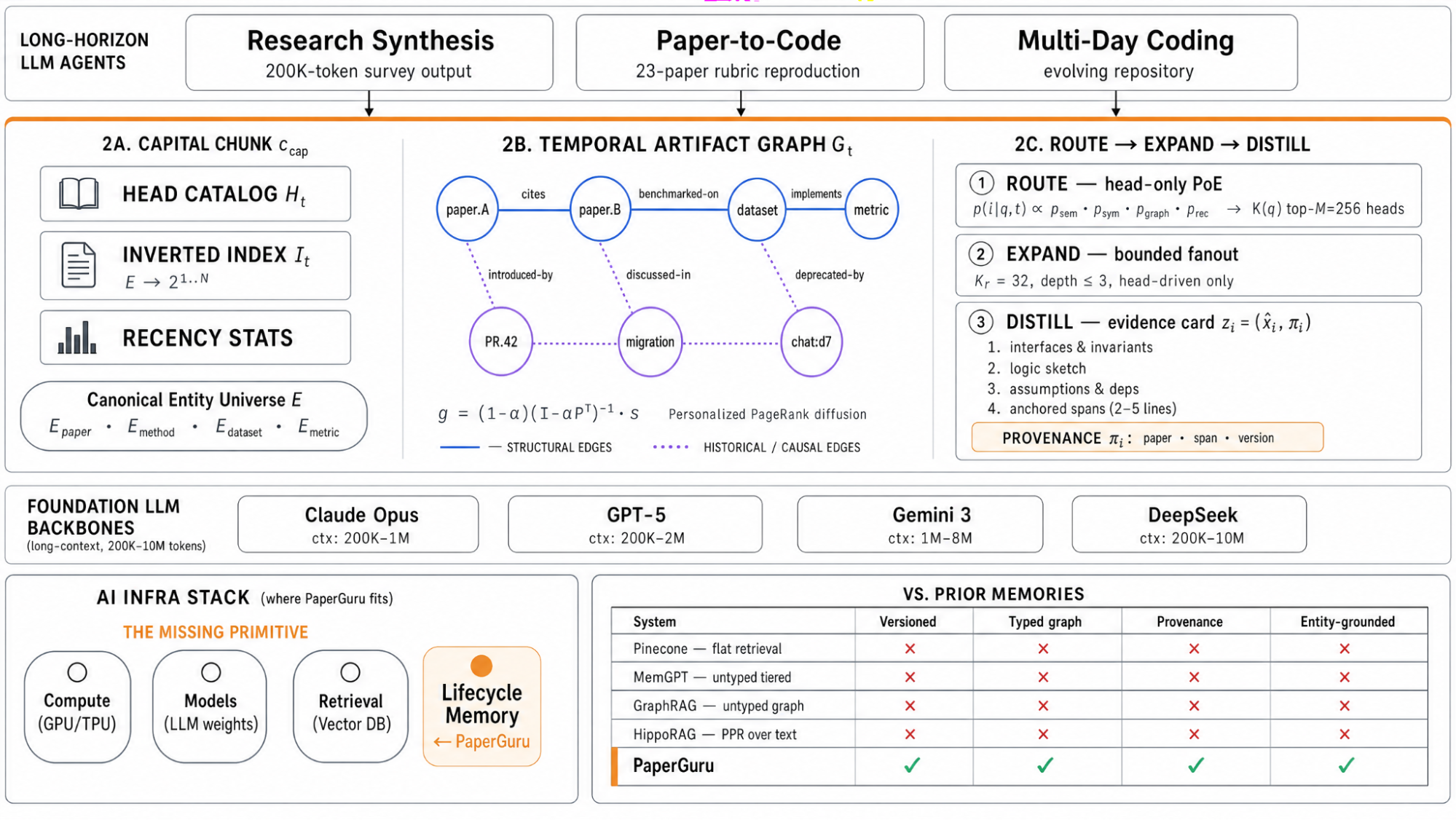
Figure 1. PaperGuru's product architecture. PaperGuru sits as the lifecycle-aware long-term memory layer between long-horizon LLM agents and foundation backbones, powered by the CCM kernel.
State-of-the-Art on the Toughest Benchmarks
We evaluated PaperGuru on the two most rigorous published long-horizon benchmarks: PaperBench and SurveyBench. The results demonstrate that the same algorithmic memory mechanism delivers unprecedented gains across entirely different tasks.
PaperBench: Crushing the Human-Expert Bar
PaperBench is the flagship paper-to-code reproduction benchmark, widely regarded as the toughest open audit of an agent's ability to faithfully replicate a recent ML paper given only its PDF.
PaperGuru reaches a per-paper mean of 66.05% across all 23 papers, delivering a massive +30.21% lift over the strongest published baseline (AiScientist + GLM-5).
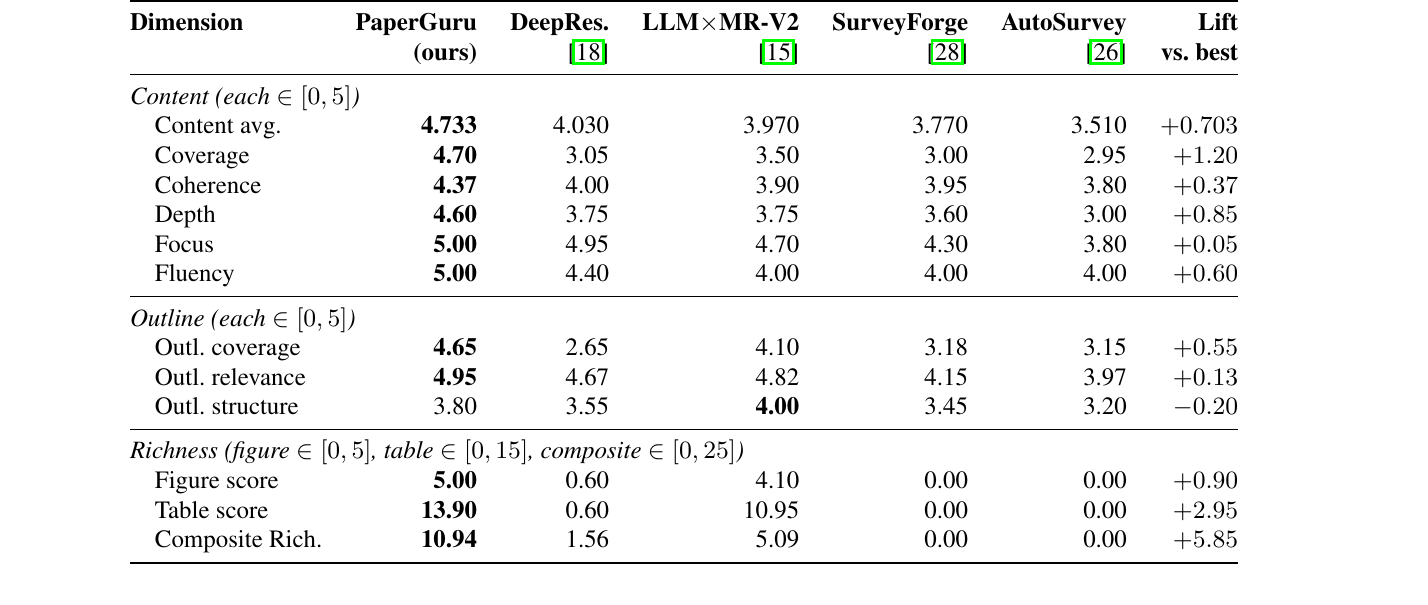
Table 1. PaperBench headline scores. PaperGuru achieves 66.05%, far exceeding the 41% human-expert baseline.
More importantly, PaperGuru clears the 41% 48-hour ML-PhD human-expert bar on 7 of the 23 papers, with the highest score reaching 95.45%.
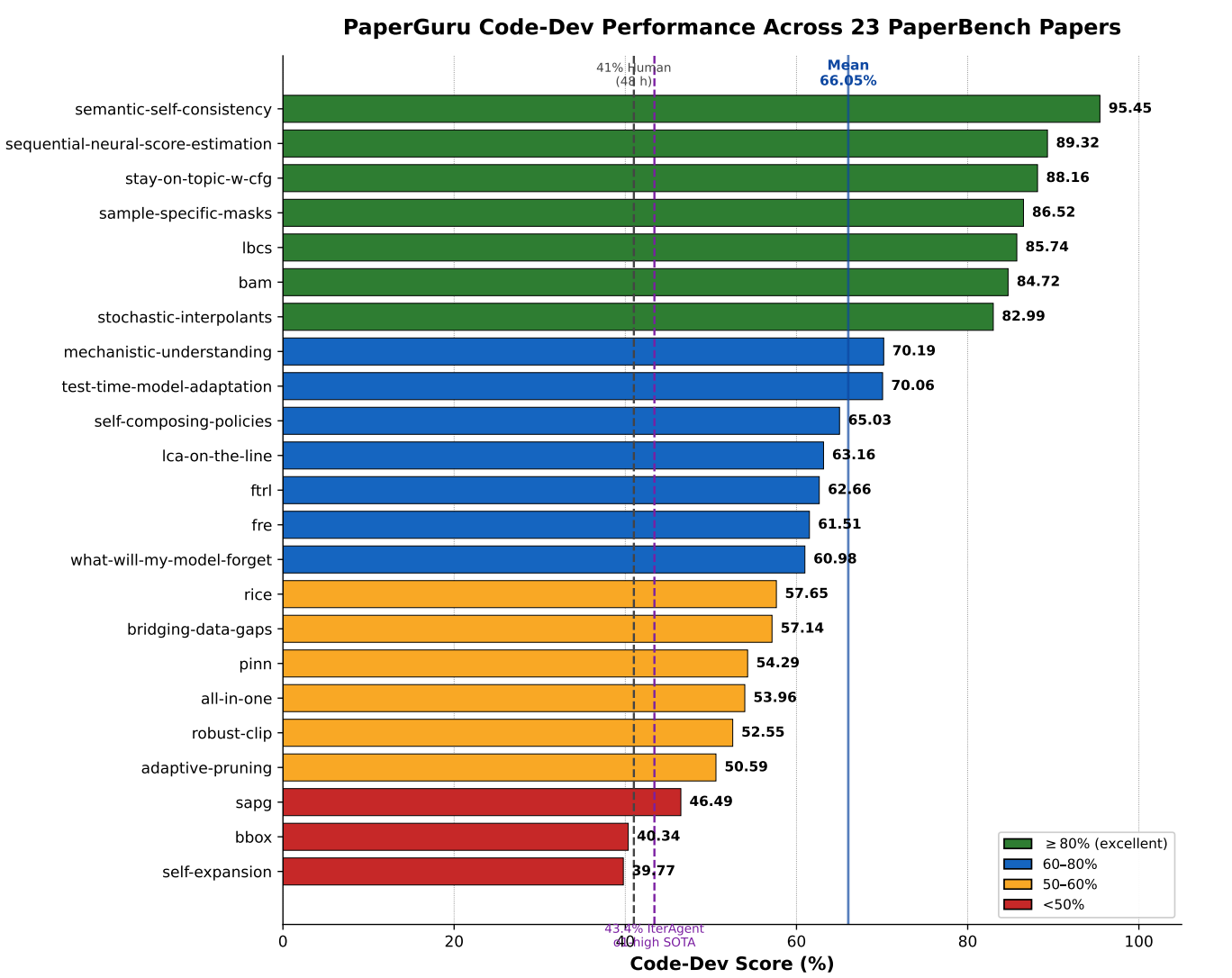
Figure 2. PaperGuru scores across the 23 PaperBench papers. The vertical reference line is the 41% 48-hour ML-PhD human-expert baseline; the horizontal reference line is the 66.05% PaperGuru mean.
SurveyBench: Redefining Long-Form Synthesis
SurveyBench is the canonical evaluation of long-form scientific survey writing, where the memory must sustain a 200K-token output with citation-grounded figures and tables.
Under the official claude-opus-4.7 judge, PaperGuru reaches a content score of 4.733, an improvement of +0.703 over the strongest published baseline (OpenAI DeepResearch).

Table 2. SurveyBench scores under the official claude-opus-4.7 judge. PaperGuru achieves the highest scores across almost all dimensions, including Coverage, Depth, and Fluency.
But the most striking gap is in structural richness. PaperGuru achieves a composite richness score of 10.94, a +5.85 absolute lift over the runner-up. This gap is driven by PaperGuru's version-consistent provenance mechanism: every figure and table emitted is grounded in an evidence card carrying a stable edge to the cited source paper.
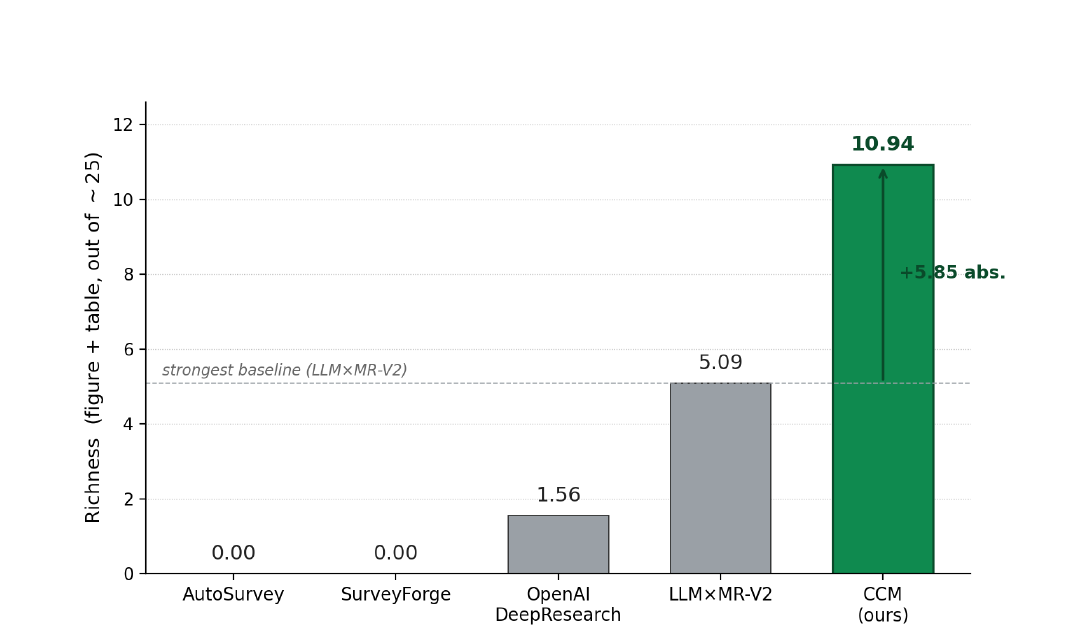
Figure 3. SurveyBench richness (figure + table). PaperGuru reaches 10.94 vs. the strongest baseline's 5.09. Lower-ranked baselines emit zero tables and zero cited figures.
Real-World Validation: 10+ Acceptances in Month One
Benchmarks are only proxies for real-world utility. To prove PaperGuru's readiness for production science, we conducted an end-to-end deployment study covering more than 30 manuscripts written with PaperGuru-backed memory.
In just its first month, 10 papers have already been accepted at peer-reviewed venues, including:
- FSE 2026 (IVR Track & Posters)
- ICML 2026 (Regular)
- ICoGB 2026
- Advanced Engineering Informatics (AEI), Elsevier flagship journal (minor revision)
With 30+ further submissions currently under review at NeurIPS, CCS, and adjacent top-tier venues, the evidence is clear: PaperGuru's memory architecture transfers far beyond controlled benchmarks into the messy reality of academic publishing.
The Future of AI for Science
The future of academic writing isn't an AI that writes instead of you. It's an AI research studio that handles the friction—literature discovery, citation formatting, and data provenance—so you can focus on the science.
PaperGuru is not just a tool; it is the missing infrastructure layer for the AGI era of research. By solving the long-term memory problem, we are enabling agents to operate over evolving scientific archives with the rigor and traceability that peer review demands.
Ready to publish smarter?
Start your journey with PaperGuru today. Sign up at paperguru.ai and get your first 500 credits on us. No credit card required.